우선 예제로 쓸 데이터프레임을 하나 생성한다.
import pandas as pd
df = pd.DataFrame({'ID' : ['c_01', 'c_02', 'c_03', 'c_04', 'c_05', 'c_06'],
'Type' : ['a', 'a', 'a', 'b', 'b', 'c'],
'Rank' : [1, 1, 2, 2, 2, 3]})
df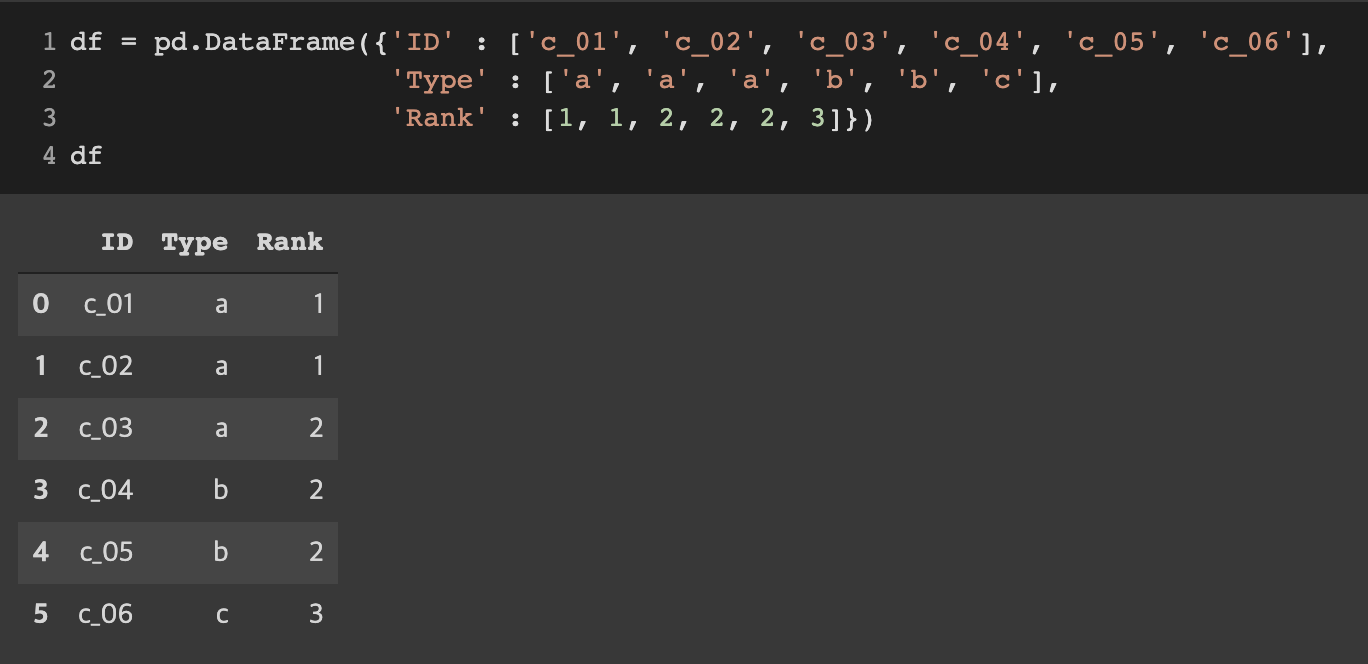
DataFrame.duplicated(subset=None, keep='first')
중복 행 확인하기
subset은 중복을 확인할 열을 [리스트 형태]로 입력한다. default는 모든 열에 대해 중복을 확인한다.
keep은 first, last, False 중 선택한다. default는 first.
keep='first' 이면 중복 행 중 첫번째 행만 False, 나머지 행은 True.
keep='last' 이면 중복 행 중 마지막 행만 False, 나머지 행은 False.
keep=False 이면 중복 행 모두 True를 반환.
위에서 만든 데이터프레임을 Rank열의 값을 기준으로 중복여부를 확인해 본다. keep='first'
dup = df.duplicated(['Rank'], keep='first')
dup
중복여부 column을 기존 데이터프레임에 열 추가를 통해 비교하기 쉽게 확인해보자.
dup 에서 keep='first' 이므로 인덱스 기준 Rank가 1로 중복되는 0행, 1행 중 첫번째인 0행의 Dup값이 False로 되고 1행은 True가 된다.
마찬가지로 Rank가 2로 중복되는 2행, 3행, 4행 중 첫번째인 2행의 Dup 값이 False, 나머지 3행, 4행의 Dup값은 True가 된다.
5행의 경우 Rank를 기준으로 중복되는 행이 없으므로 Dup 값이 False 이다.
df_dup = pd.concat([df, dup], axis=1)
df_dup.rename(columns = {0 : 'Dup'}, inplace = True)
df_dupDataframe column 명 변경 참고 :
2021.10.21 - [python] - [python] Dataframe column 명 변경, column 순서 변경

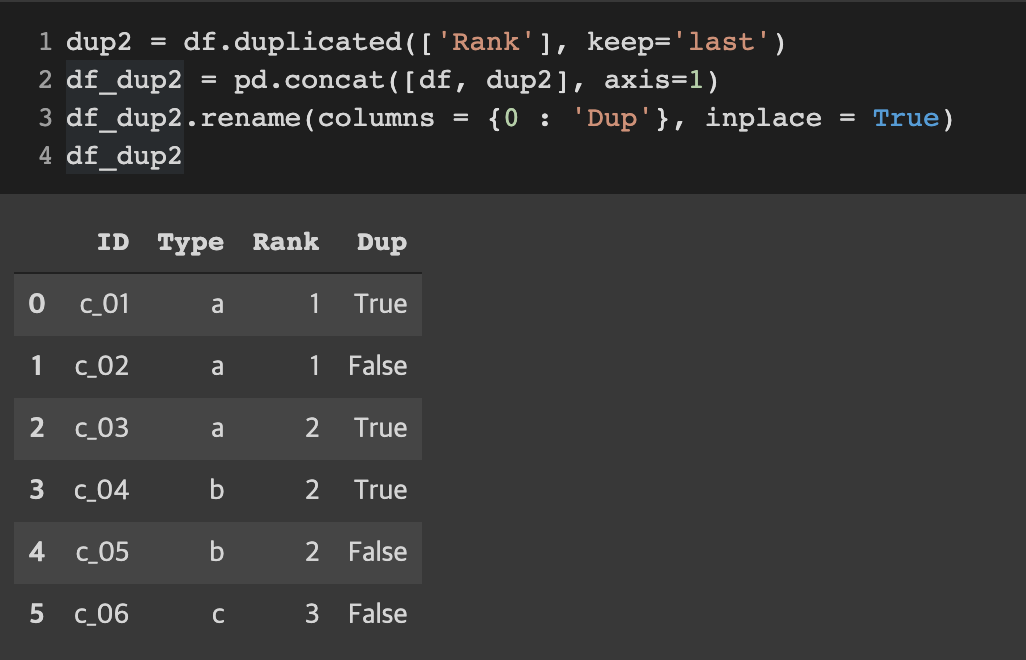
keep='last' 일 때 결과
중복 행들 간에서 마지막 행들이 False를 반환하고 나머지 위의 행들은 True를 반환한다.
dup2 = df.duplicated(['Rank'], keep='last')
df_dup2 = pd.concat([df, dup2], axis=1)
df_dup2.rename(columns = {0 : 'Dup'}, inplace = True)
df_dup2
keep=False 일 때 결과
중복 행들 모두 True를 반환한다. 중복 행이 존재하지 않는 행만 False를 반환한다.
dup3 = df.duplicated(['Rank'], keep=False)
df_dup3 = pd.concat([df, dup3], axis=1)
df_dup3.rename(columns = {0 : 'Dup'}, inplace = True)
df_dup3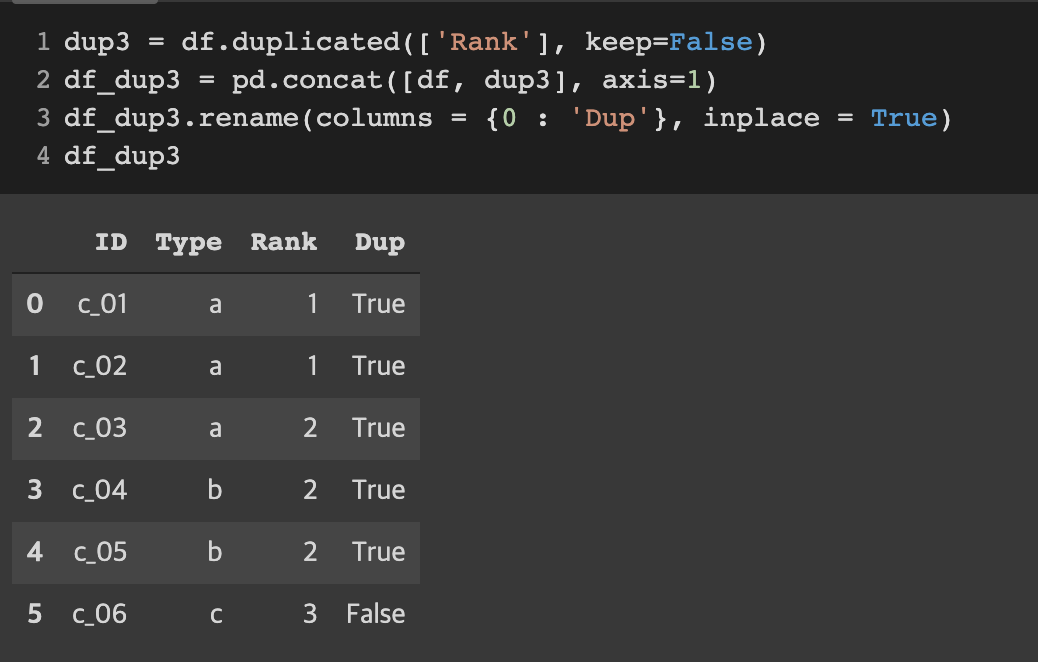
중복 열 2개를 기준으로 중복 행 확인하기
dup4 = df.duplicated(['Type', 'Rank'], keep='first')
df_dup4 = pd.concat([df, dup4], axis=1)
df_dup4.rename(columns = {0 : 'Dup'}, inplace = True)
df_dup4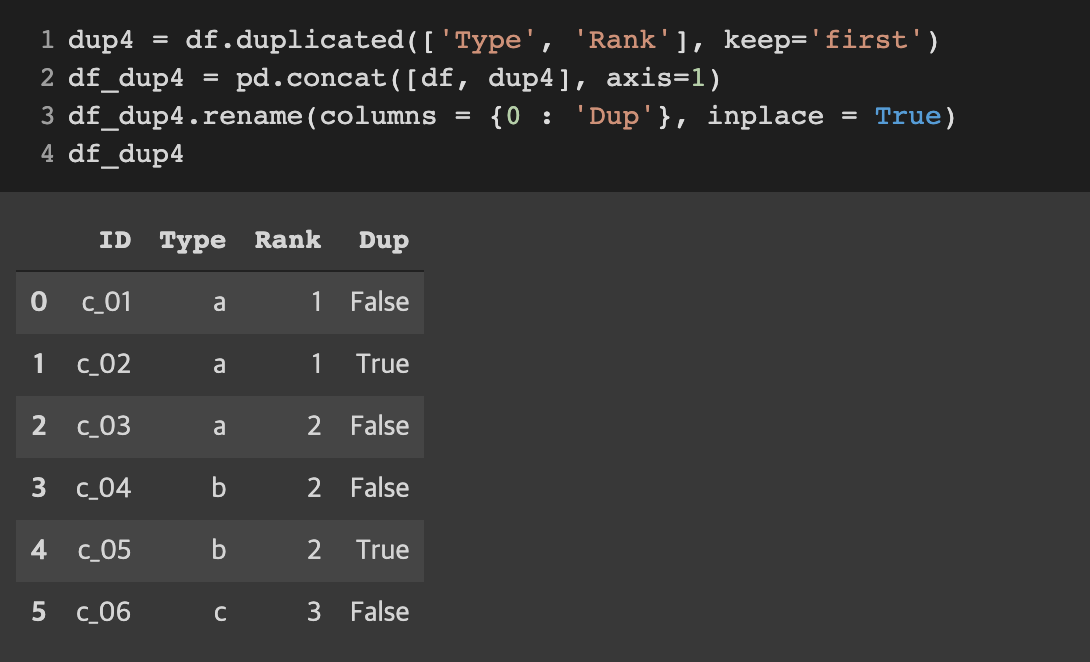
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
중복 행 제거하기
subset은 중복 행 제거를 위해 중복을 확인할 열을 [리스트 형태]로 입력한다. default는 모든 열에 대해 중복을 확인해 제거한다.
keep은 first, last, False 중 선택한다. default는 first.
keep='first' 이면 중복 행 중 첫번째 행만 남기고, 나머지 행은 모두 제거.
keep='last' 이면 중복 행 중 마지막 행만 남기고, 나머지 행은 모두 제거.
keep=False 이면 중복 행 모두 제거.
기본 데이터프레임

keep='first' 일 때 duplicated 반환 값 열 추가

데이터프레임에 drop_duplicates를 적용하면 duplicated의 결과가 False인 행만 남고 True인 행이 제거된다.
keep='first' 일 때 drop_duplicates
df.drop_duplicates(['Rank'], keep='first')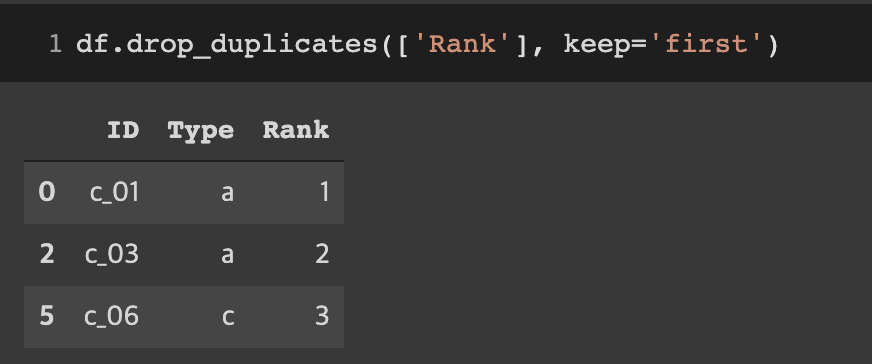
keep='last' 일 때 duplicated 반환 값 열 추가
keep='last' 일 때 drop_duplicates
df.drop_duplicates(['Rank'], keep='last')
keep=False 일 때 duplicated 반환 값 열 추가

keep=False 일 때 drop_duplicates
df.drop_duplicates(['Rank'], keep=False)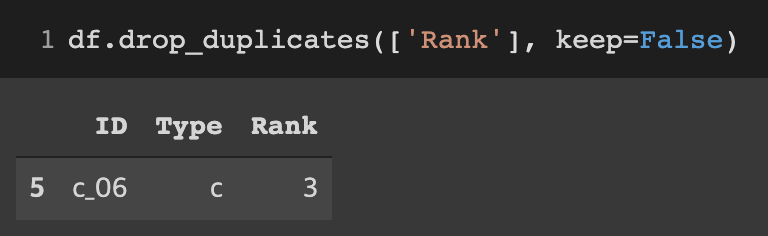
참고 :
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.duplicated.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
https://kongdols-room.tistory.com/124
'Python' 카테고리의 다른 글
| [python] 파이썬 람다 함수 사용하기 (python lambda expression) (0) | 2021.10.25 |
|---|---|
| [python] Dataframe column 명 변경, column 순서 변경 (0) | 2021.10.21 |
| [python] 문자열 분리하기 합치기 ( split / join ) (0) | 2021.10.19 |
| [python] re.sub 정규표현식을 통한 문자열 치환 (특수문자 제거) (0) | 2021.10.19 |
| [python] 데이터프레임 내의 값이 2차원리스트 일 때 2차원 리스트끼리 합치기 (0) | 2021.10.12 |

댓글